起源是以前看过的一个B站视频。
视频里统计了中国的Bangumi,日本的Sati和欧美的Ann的评分,并取三者平均分进行排名。
总的来说,这个排名还是挺靠谱的,所以我也想做一个这样的排名,利用网页的形式展示并能够定时地更新。
利用爬虫抓信息
经某人推荐用了Scrapy这个库来写爬虫。
首先很简单通过每个网站的列表可以得到动画名和url, 由于ann上默认是英文名,所以必须去爬取每个动画的详情页来获得日文名,sati和bgm上都是能直接得到日文名的,所以并没有去爬取详情页。
这些存入数据库后就开始下一步
统一信息
这是最麻烦的一步了,因为各个站点的命名并不统一,就算你使用了很多的规则去匹配也不可能做到100%准确的,还是需要人工检查。虽然如此,当然能用程序匹配得越多越好了。
匹配当然需要通过原日文名,于是我观察了一下sati和bgm上的日文命名区别,写了一些规则:
- “ミス・モノクローム -The Animation-“ 在SATI中没有 ‘-‘ 符号
- ‘!’ 在SATI上是 ‘!’, 在ann和bgm上不确定
- bgm可能会比sati多个副标题 如 ‘攻殻機動隊ARISE’系列
- 标题间的空格可能会不相同
- sati会在剧场版动画名前加上 ‘劇場版’ , 而bgm不会
- sati可能会在标题尾加上括号并有补充内容
当然这些并不是很全,实际在匹配时用了精确到模糊的查找。
- 将原标题中的’劇場版’和前后空格去掉,将一些全角符号替换成半角的
- 精确查找,考虑到有括号补充内容的问题,也同样将括号去掉的内容和括号内的内容进行精确的查找
- 考虑到标题中的特殊字符存在或有其他替代的不确定性,先将它们使用’_’通配符进行匹配,匹配的符号
re.compile(ur'[-+・\'!-:.\(\)\s]'), 这里还少了个 ‘~’,因为使用正则表达式替换会出现替换两次的问题,我就使用replace函数进行替换了。 - 考虑到空格的不确定性,直接使用’%’通配符替换了标题中的所有空格
- 考虑到副标题的问题,在标题首尾加上’%’通配符
- 最后再找不到就来一次将特殊字符全部替换成’%’的匹配
前后最多匹配10次,如果在匹配中出现了多个结果就直接手工填充了,代码。(注意下,最好将查找的字段添加上索引,不然可能要搜索个几分钟)
除了标题其实还有一个特征值:放送时间。但是通过bgm网页上获取的放送时间是中文形式的,需要去format才能和其他网站匹配。后来一想bgm不还有api吗,看了下api的属性里果然有air_date的标准形式,也可以拿来筛选。
目前的进度
第一次用程序匹配完,4000多项数据填了3000多项,结果还是不够理想,毕竟剩下1000项数据也没法手工填。
于是我干脆就先删除无用数据吧,sati上评论数少于20的就不去考虑了,删了一圈,并用放送时间进行了一圈匹配(将时间相同的输出,手工填),剩下1000多项数据,其中85项未填,看了下未填项,还真是有很多坑啊。
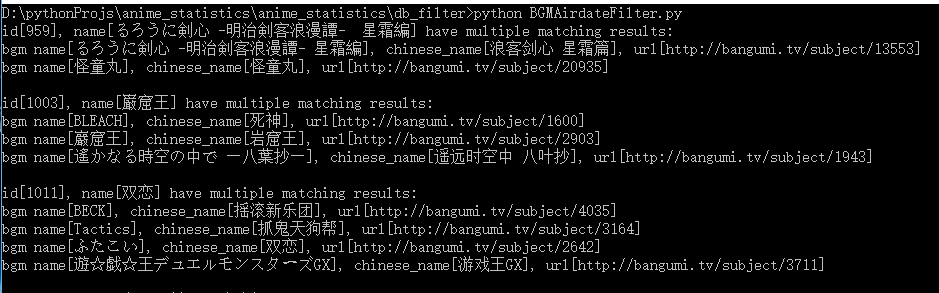
(第一条全角空格没考虑,第二条两个网站的字竟然不一样,第三条sati上使用了汉字而bgm上的日文名使用了平假名)
目前还需要手工把剩下的数据填上了。
