前言
网上关于前端监控的文章其实已经层出不穷,这篇稍微写些不一样的。近年来prometheus打开的实时指标监控的新路子越来越被大家接受,都纷纷开始基于prometheus来搞自己的监控警报体系。我们公司也是大规模使用prometheus来搞指标监控,最近打算把前端的指标也接进来,我也趁这个机会写个简单的demo以及一些思考。
使用prometheus的优势与弊端
在过去我们公司是使用elastic search来存储前端发送的事件以及处理后的数据,使用ES有个好处,可以直接满足我们两种需求:查原文和查聚合指标。本文要讨论的prometheus并不能取代ES,因为在前端监控的产品中查原文是必不可少的(比如重现某个用户的资源请求情况、查错误日志等),但是prometheus在查聚合指标时会比ES快很多,尤其是算百分位数时,相比ES的龟速,prometheus接近实时的速度可以说是最大的亮点。
当然考虑到prometheus会带来额外的开发成本,如果使用ES可以满足需求那只用ES就可以了。
整体架构
由于Prometheus是主动拉取指标的模式,所以我们需要一个类似pushgateway的服务来接收前端发来的事件并将指标聚合暴露给prometheus。整体如下
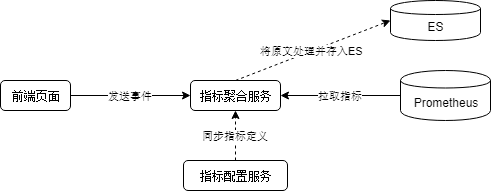
为了方便起见,下面实现的demo不会实现虚线部分。
前端采集
第一步当然就是实现前端采集指标的部分,我们通常关心下面几类指标:
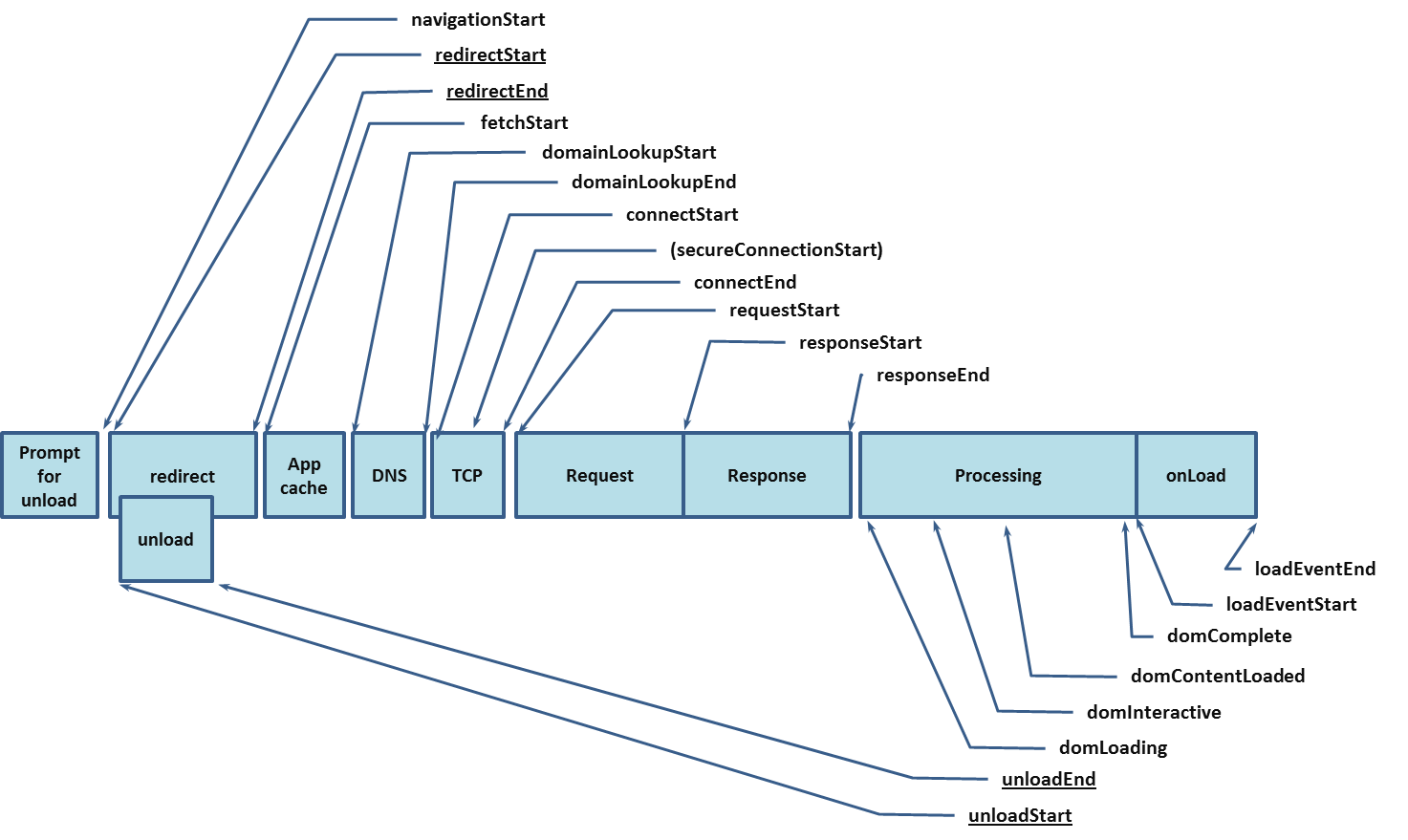
资源和页面性能指标
这类指标可以通过performance.getEntries()直接拿到,其中PerformanceResourceTiming和PerformanceNavigationTiming两个类分别包含普通资源和当前页面的性能指标,同时也可以得到paint和自定义的timing。
其中要注意的是PerformanceResourceTiming会同时包含所有ajax请求,如果你不想在这里采集到ajax指标的话可以通过initiatorType !== 'fetch' && initiatorType !== 'xmlhttprequest' && initiatorType !== 'beacon'过滤掉。
可以参考下图创建对应的指标
监听PerformanceEntry变化
通常我们会在页面加载完时获取资源指标,但是如何取监听后续新的资源呢?
最直观的方法就是使用PerformanceObserver来监听,如果要考虑兼容性的话可以使用polyfill或者用setInterval定时获取entries并筛选出新的。
AJAX指标
如果你需要通过一些详细数据(比如header、request body等)作为labels的话,就需要额外监听ajax请求了,方法是覆盖默认的fetch以及XMLHttpRequest。
错误指标
建议走自定义指标或者ES的聚合
自定义指标
约定好数据结构发送给聚合服务即可
Example
对于资源指标,我基于PerformanceObserver写了一个采集器。
对于自定义指标,由于我这里不会实现指标配置服务,所以使用了promjs这个库,但是这个库只有文本格式的输出,所以我又写了个promjs-export来导出结构化的数据,并以此作为前后端通讯的结构。
使用示例,代码如下
import { initCollector } from 'performance-resource-collector';
import prom from 'promjs';
import { exportMetrics } from 'promjs-export';
const registry = prom();
const unsupportedCounter = registry.create('counter', 'collector_unsupported_total', 'A counter for browser support for collector');
const setupCounter = registry.create('counter', 'collector_setup_total', 'A counter for collector setup');
function sendMetrics() {
navigator.sendBeacon("http://localhost:8080/custom_metrics", JSON.stringify(exportMetrics(registry)));
registry.reset();
}
initCollector({
// 将2s内新的资源batch调用
callback: (entries) => {
navigator.sendBeacon("http://localhost:8080/resources", JSON.stringify(entries))
},
// 当前浏览器不支持PerformanceObserver
onUnsupported: () => {
unsupportedCounter.inc();
sendMetrics();
},
// 监听成功
onSetUp: () => {
setupCounter.inc();
sendMetrics();
},
throttle: 2000,
});
指标聚合服务
我们需要实现3个接口:接收PerformanceEntry的接口、接收自定义指标的接口和返回规定指标格式给prometheus的接口。
资源聚合接口
资源聚合接口比较简单,因为是固定的指标,可以预先定好需要哪些指标、哪些维度,之后在代码里直接写死就好。
自定义指标聚合接口
自定义指标的聚合会比较复杂,主要是因为官方实现的client是不能修改label个数的,你可能需要自己实现一个能merge的版本。
或者采用预定义指标的形式,也就是需要一个额外的指标配置服务。
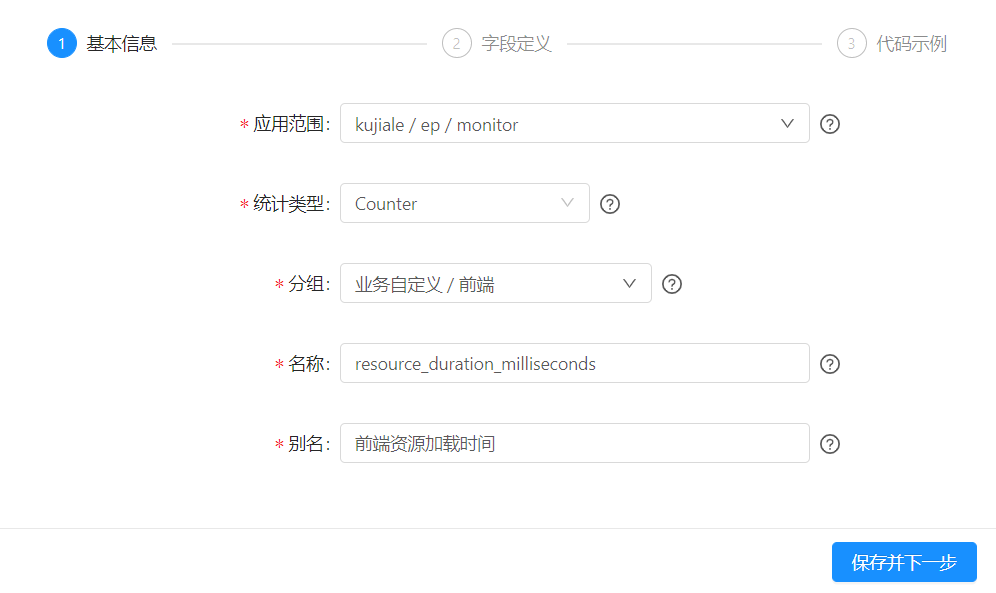
Example
因为是个demo,于是就用rust来实现了,项目地址。
这里我只聚合了资源中的duration指标以及自定义的Counter类型的指标。
另外有点需要注意的是如果是用sendBeacon来发送事件的话,chrome目前是不允许我们修改Content-Type的,所以后端的web框架可能就不会自动解析json body了,需要手动parse一下。
一个完整的demo
接下来让我们搭一个完整的demo来看看效果如何。
先把frontend-metrics-aggregation通过cargo run跑起来。
然后到metrics-collector里执行npm run pkg将example打包生成单个js。接着通过tampermonkey创建一个脚本,把前面生成的js替换进去。修改@match为想监控的网站,比如http*://*/*来监控所有站点。
最后下载prometheus,修改prometheus.yml,在最后一行的targets里添加一项'localhost:8080',并执行prometheus即可。
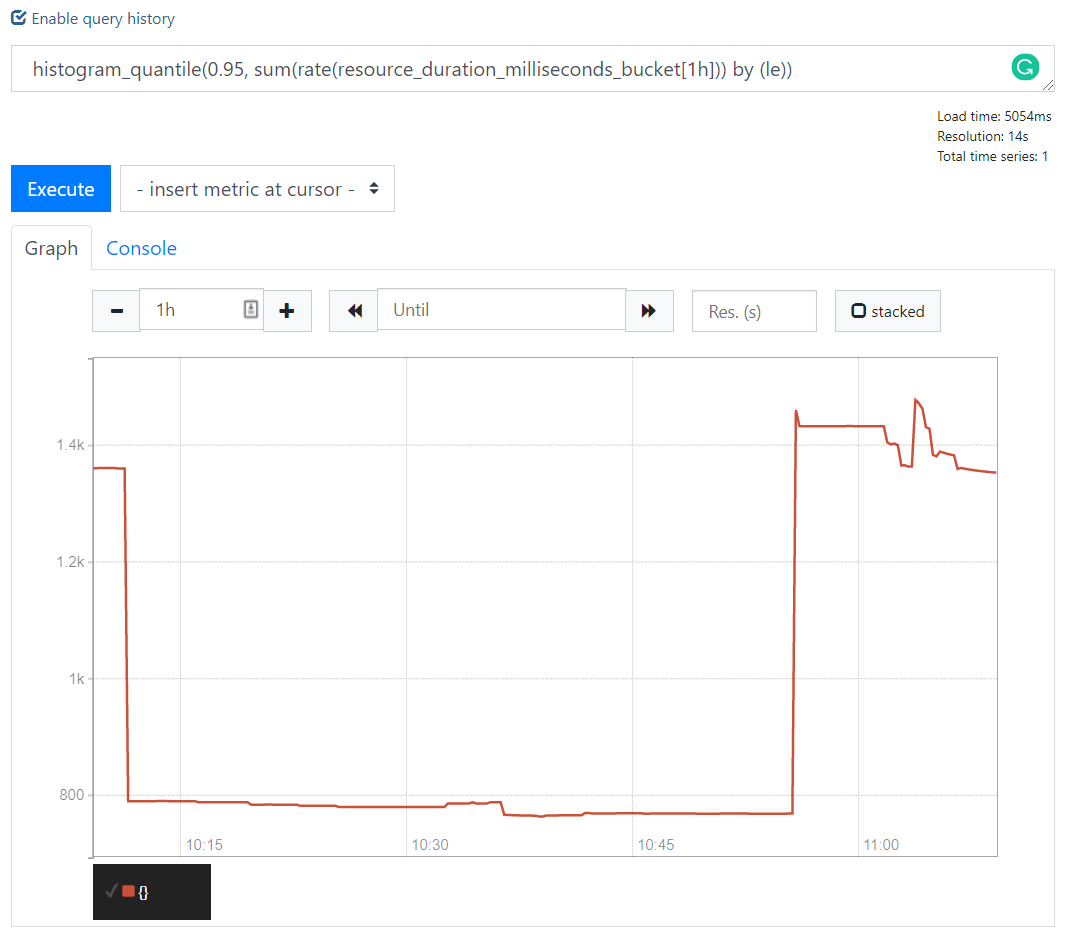
随便访问些网站,打开http://localhost:9090/graph,查询`histogram_quantile(0.95, sum(rate(resource_duration_milliseconds_bucket[1h])) by (le))`就能查看到数据了。
一些问题
使用资源的name作为label可能会导致high cardinality问题,导致查询变得很慢,你可以看到上面例子里查询一个小时的P95已经需要5秒了,此时name数量大概是4500。所以建议不要采集一些易变的、带参数的资源,比如下面在B站采集的一些图片。